
The Shape of Words
Introducing two poetic prototypes to explore AI's spatialisation of language. Using parallels with how early audio recordings translated sounds into visible waveforms for storage and reproduction.

In 1853 an attempt to recreate the human ear to “photograph the word” led to the first objective ‘spatialisation’ of a sound, a line drawn from vibrations that could be reverse-engineered to reproduce the same sound that had been recorded.
Physical vibrations had been understood to be the cause of sound for at least 200 years but what Édouard-Léon Scott de Martinville’s phonautograph allowed was a physical and repeatable notation to record what previously could only be heard in a fleeting moment. In 1860, Scott’s phonautograph traced a line from vibrations of sound at that moment. This line is now considered the earliest sound recording and in 2008 was digitally decoded to give us a haunting rendition of Au Claire de la Lune.


The initial intention of Scott was to make a machine that could write words from what it heard, the hope was that the lines drawn by the machine would act as a sort of shorthand that could be later translated into full texts. However, the phonautograph’s influence has been much broader and includes the entire history of sound recordings. The same waveform principle has been applied to the physical undulations in vinyls, magnetic fields in tapes and now our current era of digital representations.
Although the visualisation of waveforms is not interpretable by humans, they still possess a certain authenticity due to their physical form which, beyond music production, has been relegated to music videos and kitschy souvenirs.

What the phonautograph did with sound, AI is doing with language. The training of AI models is a mapping process that plots coordinates for elements within the data set. The model identifies patterns for how similar words are to one another across several axes to determine specific coordinates. Once trained, these models create a space filled with words at fixed locations. I have created a couple of prototypes that act as vehicles to explore this unchartered territory.
Word placement beyond sentences
Language already has some spatial qualities. Each word is a node, linked to one another by their type, context and common usage. Gateway words lead us into unfrequented territories acting as keys to metaphors and associations. By asking you to consider the topography of this sentence

Whilst whimsical and perhaps even poetic, the spatial relationship here serves only as a representation of hills. The placement of words hopes to evoke associations with the implied landscape.
The spatiality of words also extends beyond the page. STOP lives in an octagonal red road sign. Calvin Klein pokes his head above the trouser line. And Do Not Enter defines boundaries of privacy, intrigue, and danger. These locations are chosen by an author, not in the traditional sense but still, someone using words to bring into being their projection of the world. Perhaps the most influential authors are those whose words have real physical power behind them. Given enough muscle could anyone win a Pulitzer?
Knowing where words usually appear allows authors to conform or break with terms and phrases that are inextricably ______ to one another. This constraint offers opportunities for synonymous replacements, surprise punchlines or comedic Freudian slips.
AI’s objective linguistic space
In my last post, I suggested that AI poses a new spatial representation of language. One that gives access to associations both familiar and strange. Associations without definite explanation, that force each connection to be interpreted as a mistake or part of an unknown pattern. This post is not an attempt to fetishise AI’s newness but to suggest ways it can be understood.
Cambridge Digital Humanities’ 2021 fiction-theory uses histories of linguistic randomness and automation to understand AI writing. Their beautiful references to Tristan Tzara, Oulipo and the hyperstitional effects of fiction provide a rich set of analogies I will use to venture beyond traditional linguistics. In this new world, words can be explored through their spatial relationships as defined by AI.
Until the late 20th century, relationships between one word or concept to another had been defined by a human author to be interpreted by another human. This largely occurred in dictionaries, thesauruses and encyclopaedias since at least the first century AD (with a dramatic history starting at the first extant encyclopaedia’s author sailing towards an erupting Vesuvius in search of new knowledge).
With AI, words (or other training data), are organised using embeddings, a set of numerical coordinates that work in the same way as those on a map. AI uses these coordinates to find the proximity (geometrically and semantically) of one word to any other. However, rather than the two dimensions on a map (the x and y axis), in an AI embedding model each word has coordinates that are hundreds and sometimes thousands of numbers long. This means the words are organised in a space with hundreds or thousands of dimensions.
High-dimensional space is confusing at first and can’t be visually represented. But, for anyone who has ever played Top Trumps, you have already effectively dealt with it. The dinosaurs below have six variables which act as coordinates in a six-dimensional space. By mapping these dinosaurs’ metrics within this space, we could uncover insights about their similarities and possibly identify correlations between dimensions. Most importantly, of course, it would help you win by highlighting the dimensions where your dinosaur scores relatively higher than all the others.

Embeddings have been the basis of recommendation systems for decades. Let’s move away from the dinosaur dimensions to a practical example, films. For the coordinates, we could use the numbers associated with run time, IMDb score, release year, budget etc. (qualitative data can also be used but adds complication for this example). Now if you picked any film on the map you could find those considered similar to it based on their proximity in this space. It is also possible to do this with qualitative data by
The simple thing to understand here is that each word (or dinosaur, or film) has a set of numerical coordinates that identify its position and therefore how near or far it is from any other word in this space.
The dimensions are not predefined or easily understandable in the AI embedding models that power things like ChatGPT. The coordinates of each word are defined during the AI model’s training where it learns to identify patterns in the training data. Without human supervision, the AI develops its own set of criteria to determine the similarity of words. Some rules mirror conventional understandings of language as shown in Stanford’s 2014 GloVe project and the 3D graphs below where a directional relation implies a linguistic rule. In the first example, male to female is a vector moving down and to the right.

These geometric language relationships are partly responsible for the wide adoption of ChatGPT and similar applications. However, it’s usually hidden within the layers of larger systems. What if we could explore these ‘word spaces’ as novel forms of human-AI interaction? What ways of relating to words and AI may arise?
Experiments in spatial language
The new possibilities of recording and creating sounds using lines drawn from vibrations in 1860 present analogies for exploring the potential of AI’s novel spatialisation of words. Similar to how the first sound recordings converted vibrations into visual lines, these models turn sentences into a network of connections between each word’s coordinates. Just as the lines drawn from the first sound recordings could be reverse-engineered to produce a sound, we can trace a path through the embedding space to generate a sequence of words.
I have made two Poetic Prototypes™ that act as a new interface to explore AI’s spatialisation of language.
1. words 2 space
The first lets you build a shape using words by finding their coordinates in a two-dimensional compression of OpenAI’s embedding model. This can be done word by word or whole sentences at a time. Each word adds a new line to the emerging shape of your sentence. For example, if I start with “Should I compare thee” the zig-zag drawn below emerges.
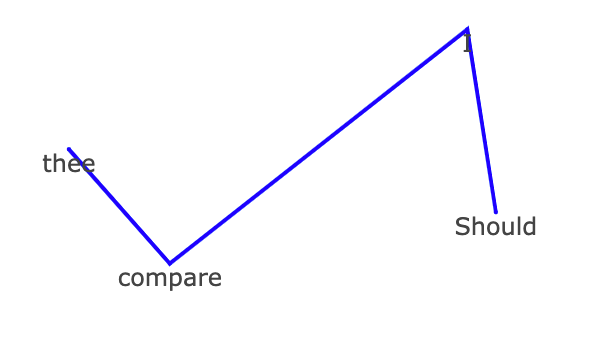
If I continue this as expected we get the intersecting triangles on the left. But if I swap in a few words for their opposites (replacing I for you, thee to me and summer to winter) we get something that looks more like a Nordic rune or an abstract digital snake.
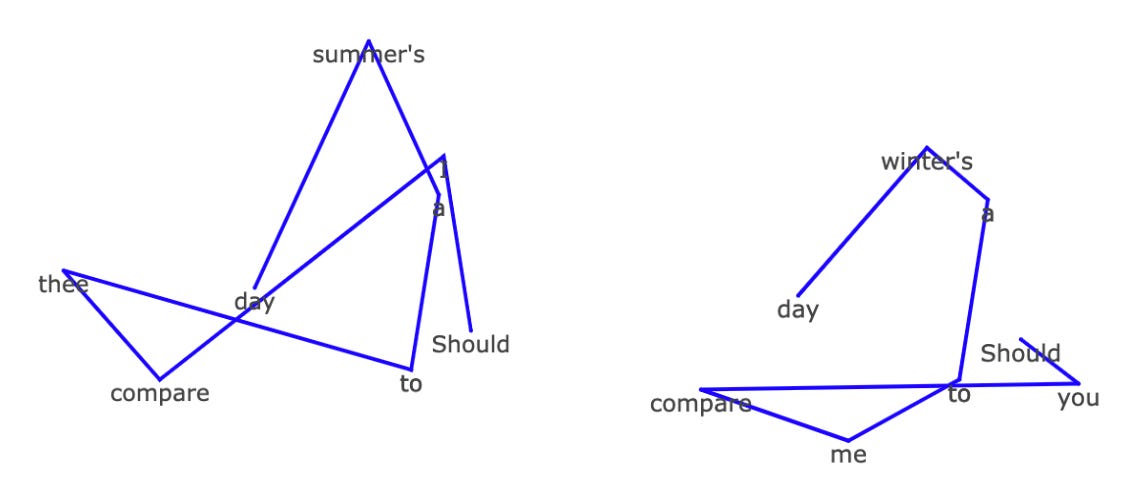
In asking questions of the spatial relationships we find linguistic intrigue and inspiration. What word would be halfway between winter and summer? What words could be used that break out of this cluster? What kind of sentences produce aesthetically pleasing shapes?
These shapes are not just representations of the sentence you have written, they are the sentence. If the shape was re-entered into OpenAI’s embedding model it would recreate the sentence exactly.
2. space 2 words
The second prototype reverses this process allowing a simulation of drawing a shape directly on the embedding space that is converted into words that correspond to each point plotted.
A simple drawing of a face below becomes the abstract sequence
“envying cardinals octuplets hikes envying cardinals octuplets authoritative cicadae bathtub nunneries authoritative multivariate conferrer analogical fits adventuresses antitumoral crocked undramatically effluvial cereus”
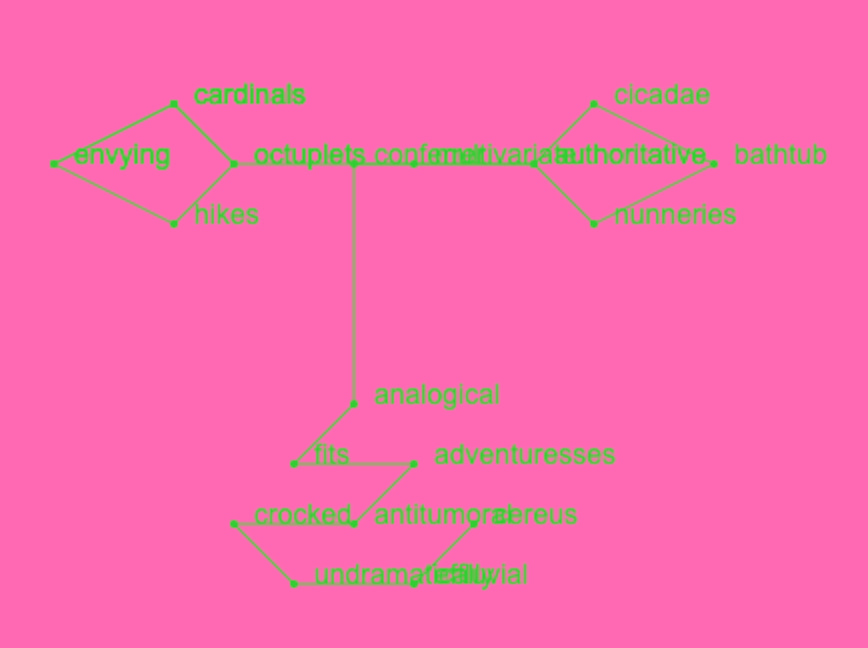
A changing linguistic relationship
Throughout this project’s development, I have been reminded of the alien language in Arrival, which asks the question of how new linguistic forms can change our perceptions of the world around us. I’m only in the first week of these projects but have already found myself interpreting words slightly differently.
With a move towards more personalised AIs, will sharing our own linguistic spatial models become an act of getting to know how someone else thinks? Will we start to see people with the shape of their favourite lyrics tattooed on their body or as a piece of jewellery?

The initial intention is to demonstrate a new form of generative poetry writing, inspiring beyond common patterns. However, this project will continue to explore the novel reality that all words have spatial qualities in AI embedding models. I will continue developing these prototypes so I welcome any interpretations or creations you would like to share.
Is it simply a poetic realisation that words and shapes are now interchangeable and precisely translatable in both directions? Or does this change how we and AI perceive space and language?